

Identity and Access Management (IAM) lies at the heart of cloud security. Applying Zero Trust (ZT) to the cloud requires “tightening” IAM policies – limiting identities’ access to cloud resources such that they are only allowed to interact with those resources that are actually needed to perform daily job functions. In this blog, we describe an automated IAM improvement technique IAMAX that reduces the impact of compromised identities by up to 85% across several commercial cloud environments.
According to IBM’s Cost of a Data Breach Report ’22, the average cost of a data breach reached a record high of $4.35M, which is up $110K compared to the previous year. Data breaches in public clouds are even more costly: $5.02M. Additionally, 45% of data breaches occur in a cloud environment. As public cloud adoption continues to grow, the severity and the scale of cloud data breaches are likely to increase.
In this blog, we dive into one of the core components of the Zero Trust framework, Identity and Access Management (IAM), identify IAM misconfiguration issues, and present a novel AI-based framework IAMAX to automatically generate provably correct IAM policies, which brings an organization’s cloud security posture to a completely new level. The blog is based on the research paper “Using Constraint Programming and Graph Representation Learning for Generating Interpretable Cloud Security Policies” that has been published and presented by Mikhail Kazdagli at the top-tier AI conference, IJCAI’22!
Specifically, we will cover the following topics:
- Challenges with cloud IAM
- How to measure an attack impact
- Why do we need an automated solution
- How does AI improve data and cloud security postures
Challenges with cloud IAM?
Cloud security model
Major cloud providers such as AWS, GCP, or Azure adopt a traditional access control-based security model – IAM (Identity Access Management). IAM specifies permissions granted to each identity in the system and they define what an identity can execute against a resource. For example, to access a VM instance or to manipulate data in cloud storage a user requires specific permissions. Thus, if a user would like to use an AWS S3 bucket for storing and retrieving data, they must have s3:GetObject and s3:PutObject permissions. In this blog, we will primarily focus on the AWS environment and, specifically, datastore-related permissions, but everything outlined here is equally applicable to GCP, Azure, and other types of permissions.
AWS IAM employs hierarchical access control, which means that users can be merged into groups and each group may include both users and other groups. Permissions can be assigned to both users and groups. However, DevOps teams prefer working with a small number of permission groups to ease permission management. Therefore, analogous to the example above, those S3 permissions can now be assigned to a group for a set of users who require access to the same S3 bucket. If a new user requires the same set of permissions to access known datastores, they can now simply be added to the group. (AWS introduces hybrid security primitive – a role, which is similar to a group in the context of IAM refactoring, therefore we omit roles from the further discussion.)
Dormant permissions
Group and role-level permission management comes at a cost. The process of adding users to groups and provisioning access to multiple datastores for the group at once, creates unwanted access paths, especially in a large environment. This is because the permissions that are assigned to the group over time, are based on the needs of a subset of users. Some users within the group may not require access to certain datastores that the entire group is provisioned for. For example, Figure 1a shows a user user1 typically only accesses the datastore datastore1. However, because it is part of the same group, it also has access to the two other datastores datastore2 and datastore3. Symmetry DataGuard classifies such unwanted access paths as dormant.
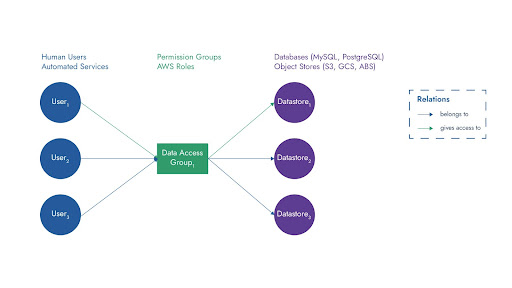
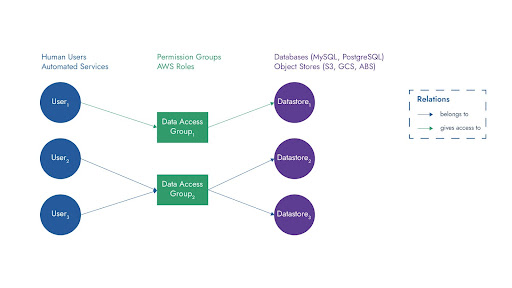
Figure 1: a) Traditional User-Group-Datastore relationships. b) Ideal relationship targeted using the IAMAX approach.
Unfortunately, dormant permissions are prevalent within large and/or fast-growing organizations for the following reasons: First, admins and DevOps teams usually prioritize execution, development, and convenience over security in a fast-pacing development environment. Second, existing IAM policies deteriorate over time as the organizational structure evolves especially for larger entities, i.e. employees move between projects/teams. Third, provider-managed IAM policies are usually overly excessive since they are created based on the provider’s ballpark estimation of what the role requires. These cases create over-permissioned users that pose a significant security risk to a company. If a user gets compromised, attackers may get access to additional business-sensitive data because of these dormant permissions.
How to measure an attack impact?
Data blast radius
As the dormancy among user-datastore access paths increases, the scope of abusing such dormant permissions also increases, which we can quantify using the Data Blast Radius. The data blast radius for the identity is simply the number of datastores that the identity can reach. The data blast radius of an environment, consequently, represents the cumulative blast radiuses observed across all identities in the environment. For example, the data blast radius in this original environment configuration for user user1 is 3 (Figure 1a) because user1 can access datastores datastore1, datastore2, and datastore3. The same data blast radius value holds true even for users user2 and user3 since they also have access to the same datastores. The environment’s data blast radius is the sum of the data blast radiuses for user1, user2, and user3, which is 9 (3 + 3 + 3). We aim to reduce the data blast radius for the environment with our novel AI-based technique called IAMAX. Figure 1b shows an improved grouping that reduces the data blast radius to 5 (1 + 2 + 2) by completely removing dormant permissions.
Why do we need an automated solution?
IAM policy deterioration poses a unique challenge: policies need to be periodically refactored to adjust permission groups and remove dormant permissions. Though this can be done manually to some extent, any periodic task is a good candidate for being automated with AI. IAMAX framework minimizes risk coming from poorly designed or deteriorated IAM policies. Symmetry Systems’ DataGuard already provides visibility into the relationship between various cloud actors such as users, groups, roles, and datastores thanks to flexible deployment models. IAMAX leverages this information when refactoring existing IAM policies.
How does AI improve data and cloud security postures?
Declarative IAM specifications
The novelty of our approach lies in a declarative approach to designing IAM policies. Specifically, we declare security requirements that refactored IAM policies should adhere to in order to be considered secure. Thus, we shift focus from actual implementation (i.e. manually configuring individual groups and roles and assigning specific permissions to them), to the specification of semantic properties of secure IAM policies. AI automatically converts declarative specifications into actual IAM policies.
IAM policy requirements
IAMAX generates data-centric IAM policies, which provide extensive protection for business-sensitive data in the case of attackers getting into the cloud environment. Refactored IAM policies have a minimal possible data blast radius for the environment while retaining all dynamic data accesses previously discovered by DataGuard. When minimizing the total blast radius, IAMAX guarantees that there are no severely over-privileged users (outliers). Moreover, IAMAX takes extra care of separating datastores based on types of sensitive data stored in them. Note designing such fine-grained data-centric IAM policies is beyond the reach of human experts and it’s only achievable with the help of automated AI-based methods. (Details of the approach are available in the paper.)
In Figure 1a, we highlight the existing hierarchy of access provisioning where users are part of groups. To reiterate, user user1 has extraneous access to datastores datastore2 and datastore3 while users user2 and user3 can access datastore datastore1, although they don’t need this access for their daily function. Our approach to reducing the redundancy of access ideally results in new groups being generated, called Data Access Groups, where each new group strictly defines the accessibility for its own users based on their dynamic access behavior. Figure 1b shows how users in the original example (Figure 1a) will be split into two groups with stricter access control, and therefore a smaller data blast radius.
In order to convert declarative IAM specifications into actual IAM policies, we utilize constrained programming (CP). CP provides an expressive framework for modeling domain constraints, and CP solvers are able to find an optimal solution by efficiently exploring an extremely large search space. To further increase the interpretability of the newly generated IAM policies, IAMAX takes into consideration behavioral similarities between users. In this case, the similarity is defined in a more general way than datastore access patterns, as described below. IAMAX uses its best effort to assign only similar users to each data access group. We want to avoid generating an IAM policy that allows users from different departments (e.g. sales and web developers) to be a part of the same group.
To compute behavioral user similarity, we use a state-of-the-art ML approach, a Graph Neural Network (GNN) that maps users to an embedding space. User similarity is determined as a distance between user embeddings produced by GNN. Specifically, the GNN module consumes a stream of cloud operations executed by every cloud principal, represents unstructured data as a heterogeneous graph, and runs the GNN training routine that maps entities (users, roles, groups, datastores) to an embedding space. To incorporate mutually infeasible similarity constraints to further improve generated IAM policies, we apply the constraint generation technique. Note that we limit the maximum number of data access groups that can be generated, to preserve the interpretability of the refactored IAM policy.
Real-world Deployment
We evaluated our approach on eight Symmetry Systems’ customers across industries including Healthcare, Technology, and Retail. Here, we share results with respect to only a couple of metrics used in the evaluation (details in the paper):
Reduction in dormant permissions
We quantify the improvement in the robustness against an attack, through the computation of reduction in dormant permissions. Note that the dormant permission reduction is the original objective that we aim to minimize with the IAMAX approach. Figure 2 represents the improvement in dormant permissions observed across real-world environments. The x-axis represents the number of data access groups proposed by the algorithm while the y-axis shows the fraction of dormant permissions. As expected, the more data access groups we have, the higher the segregation among users resulting in the elimination of arbitrary permissions between groups and datastores (figure 1).
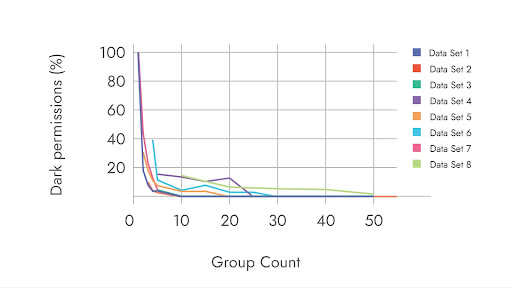
Figure 2: Improvement in dormant permissions across real-world customers
Improvement in the Blast Radius
We also subject the IAMAX algorithm against simulated security attacks where we simulate the lateral movement of different intensities (that is, compromising one, two, or three random users simultaneously) within the target environment. We then determine the attack impact by evaluating the fraction of datastores an attacker can reach with and without the refactored IAM policy. Figure 3 summarizes the results. The relative reduction of blast radius (the lower, the better) is displayed on the y-axis for every real-world customer (x-axis). IAMAX reduces the blast radius by 20%-85% depending on the environment.
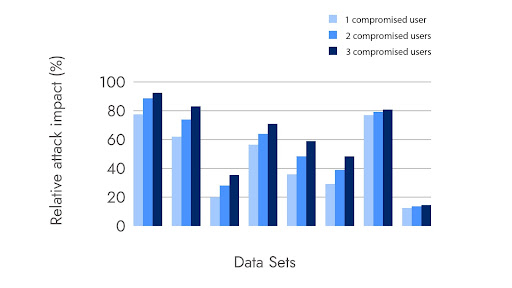
Figure 3: Reduction in the blast radius across customers
The IAMAX-based refactoring system is available for Symmetry Systems’ customers in a preview edition of DataGuard.
Note
Although the IAMAX aims to refactor IAM policies in order to protect business-sensitive data by limiting Lateral Movement, Exfiltration, and Impact techniques (per MITRE jargon) since the attacker now has limited options to span an attack across the environment. We employ this approach to data-specific configurations, however, the mechanism presented here can analogously be extended to other types of cloud permissions such as those that control interaction with cloud compute resources, Kubernetes cluster, etc.
An automated approach to monitoring and updating the IAM policies is undoubtedly critical in maintaining sanity and a strict security posture. The DataGuard solution is a key tool where the IAMAX approach, along with data inventory assessment, data classification, policy-oriented monitoring, and detection capabilities provide a complete framework for an organization’s Data Security Posture Management (DSPM) strategy.




