What is a Data Perimeter?
Data perimeters are the points where access to your data is gated. In traditional infrastructure, the data perimeter is usually defined as a function of the network perimeter: if you’re “on the network”, you can get to the data. Access control in the form of authorization policies (eg: Security Groups in Active Directory) are generally employed, but there is often an inherent sense of trust for computing nodes that are within the internal network. By contrast, data access in a cloud environment is often entirely limited to access control policies. There is no network perimeter; the gateways to your data are the access control mechanisms.
Types of Data Perimeter Mechanisms
Identity-based
If access to a data resource is entirely defined within a policy associated with an IAM User, Role, or Group, it is an identity-based perimeter. Whether the policy is attached or inline doesn’t matter. What matters is that the identity, or membership in the identity, is the gatekeeper for access to a data store.
Resource-based
Access policies can also be attached to certain resources in AWS, such as S3 buckets. Resource policies allow for external accounts to have access, but can be used to provide access to identities within the same account.
Network-based
Many AWS services offer data via public APIs, but some, such as RDS or RedShift, require a network connection to the actual data resources. For resources in an AWS VPC, network access is provided by VPN, direct connection(AWS Direct Connect), VPC Peering, Transit Gateway, or the resource having a public IP address.
Also included in this category are VPC Network Access Control Lists (NACLs) and Security Groups. NACLs are set at a subnet level and can explicitly allow or deny access. Security Groups are applied to a resource and can allow access.
Derived
Some services in AWS can be granted access to data that is then made available to a user irrespective of the user’s IAM access. With RedShift Spectrum, a user with access to the RedShift cluster can query data residing in S3 buckets. The cluster needs access to the buckets, but the user does not.
Resource-specific
Some services have their own authorization mechanisms, such as database engines in RDS. With an RDS instance, access to the data within the databases is managed within the engine. If IAM authentication is enabled, broad access to a database will leverage IAM, but fine-grained access will still reside in the database engine. LakeFormation also uses its own authorization in combination with IAM. LakeFormation also leverages its own ABAC mechanism (called LF-Tags) that is not interchangeable with IAM ABAC.
Organization and Account Controls
Service Control Policies and Permissions Boundaries allow Organizations and accounts, respectively, to limit access to APIs and the data they offer.
VPC
Some AWS services, such as S3, provide the option of allowing API calls to remain within the VPC and not traverse the public Internet. While AWS API calls are encrypted using HTTPS, some organizations require all traffic to remain under their control.
Examples
Traditional Data Perimeter
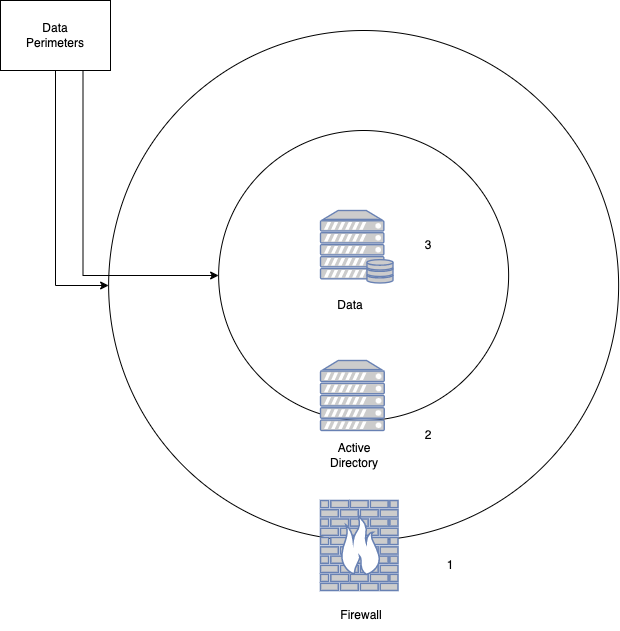
In the example above, we have a traditional data perimeter. It is defined by ingress and egress points consisting of the following:
- Network access. If you are on the “inside” of the firewall, you have network access to the data resource.
- Logical access control (domain). Authentication and authorization provided as part of Active Directory or another directory service. This is generally a user identity and access policies that permit (or deny) access to resources.
- Logical access control (local). Some resources (eg: Windows file servers) support their local access policies which can override domain policies. In general, if they’re not explicitly configured, they default to allowing all access.
AWS RDS Data Perimeter
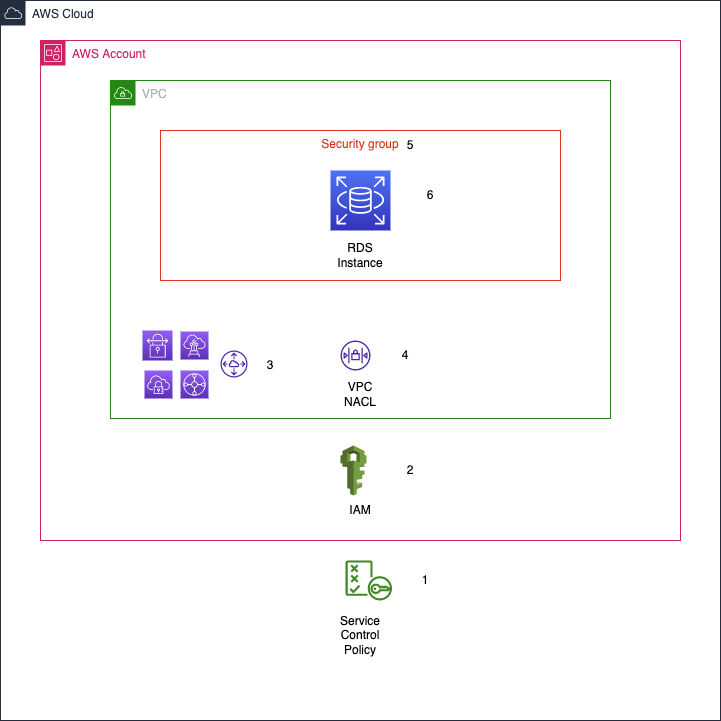
In this example, we are looking at an AWS RDS instance. RDS is database instance (MySQL, PostgreSQL, MS-SQL, etc) running on an AWS-managed node. Because it is still a traditional database, it has some similarities to a traditional data perimeter, but is much more complicated.
- Organization-level controls. AWS Organizations provide access controls in the form of Service Control Policies. These policies can block access to APIs and prevent access to a data resource.
- Identity and Access Management (IAM). At the account-level, access to APIs and resources is determined (in part) by policies attached to a user identity. IAM both authenticates and authorizes identities.
- Non-local network access. In AWS, network access to a resource requires VPN, VPC Peering, Transit Gateway, or a public IP. As a group, these components are network ingress/egress points.
- VPC NACL. A VPC includes a Network Access Control List (NACL), which specifies what traffic is allowed or blocked.
- Security Group. These function as a resource-level firewall and must be configured to allow the necessary traffic.
- RDS access control. Within the RDS instance, logical access control must be configured in the form of users and permissions.
AWS S3 Data Perimeter
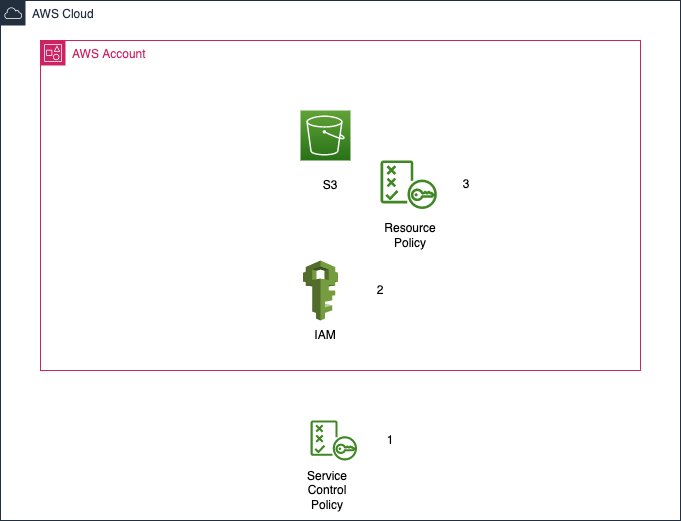
In this example, we have the fully-managed service S3. The configuration points for the data perimeter are far fewer and there is no configuration for network access.
- Service Control Policy. As with RDS, SCPs can block all access to API calls. For S3, this can result in the service being unavailable.
- IAM. This provides the same type of access control as with RDS.
- S3 Bucket Policy. This is a resource-level policy and can block any access provided via IAM.
Putting it all together
Securing data workloads requires an understanding of how access is provided to the data. For workloads in the cloud, it’s no longer as simple as ensuring that network is accessible and that a user is a member of the right Active Directory group.
When data is residing on a network-based location (eg: RDS, Elasticache, Redshift), ensure you have checked:
- VPC NACLs
- Security Groups
- VPC Peering/Transit Gateway/VPN
- IAM (both Redshift and RDS can have database engine access provided by IAM)
- Permissions Boundaries
- Organization SCPs
- Local engine permissions
When the data is residing in a non-network aware location (eg: S3, DynamoDB), verify:
- IAM
- Permissions Boundaries
- Organization SCPs
- Resource policies (eg: S3 Bucket Policies)
Takeaways
- There is no single data perimeter. Every data resource has its own data perimeter that must be managed.
- When providing access to data from outside the organization (eg: granting another AWS access to an S3 bucket), the data perimeter for that resource as expanded beyond your control.
- Derived perimeters are especially complicated. Understanding how a given service proxies access to data for your users is critical in ensuring least privilege and proper access control.
- Data perimeters in AWS are not the same thing as network perimeters or nodes. For many data sources, the network perimeter is entirely unrelated to the data perimeter. Security professionals can no longer rely on strict network controls to ensure confidentiality of their data.
- Data perimeters in cloud environments are best managed as code. Because of the complexity and sprawl in cloud environments, manually maintaining perimeters will eventually lead to unintended data exposure. Defining and managing perimeters in code enables standard software review practices to prevent exposure.




Share this entry